The NCM Industry Has an Evidence Problem. Ours Is 50,000 Devices in 21 Minutes.
The network config management industry quotes scale without evidence. rConfig pulled 50,000 devices in 21 minutes on one host. Open source test bed included.
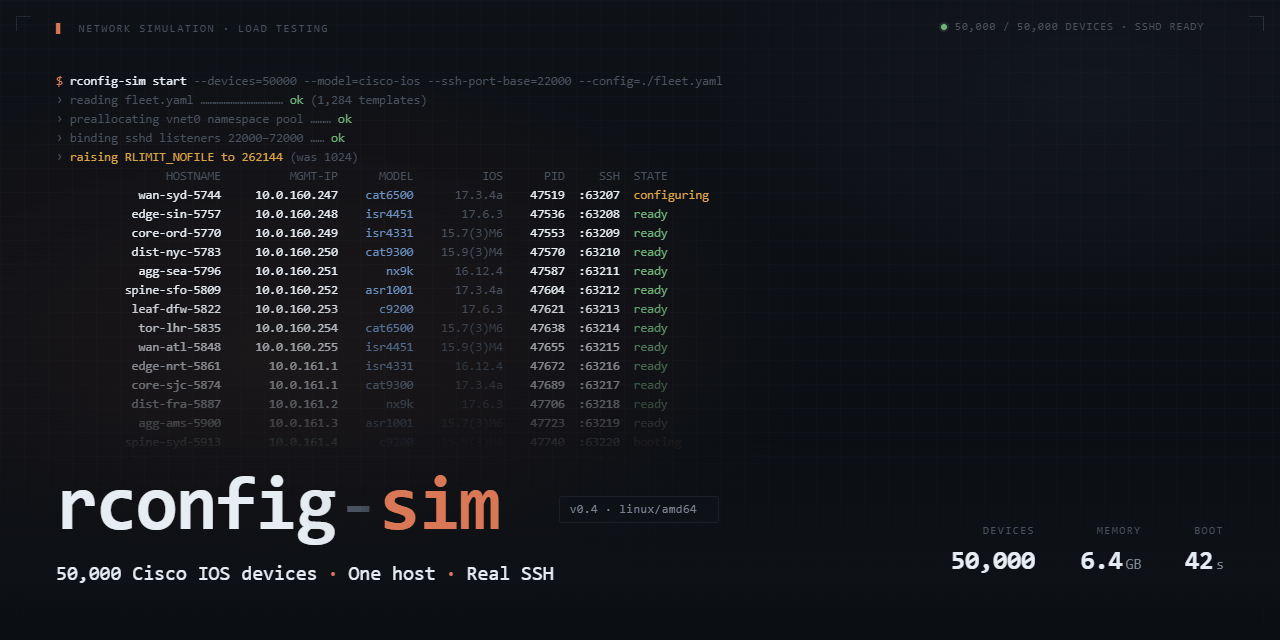
I am going to start with the result, because the result is the point.
In our lab, on a single 16GB eight-core Linux host, rConfig pulled configurations from fifty thousand simulated Cisco IOS devices in twenty-one minutes. Real SSH. Real authentication. Realistic multi-megabyte configs across a mix of small, medium, large, and huge devices. Average job time of 2.66 seconds. P95 inside six seconds. CPU at ninety-five percent, memory at 15GB, modest disk IO. No failures. No retries. No drama.
I have spent more than twenty years in enterprise networks and infrastructure. I have read every major NCM vendor's whitepaper that is worth reading. I have never seen a published config management run anywhere near this, with hardware specifications, methodology, fault injection, and a reproducible test bed attached. Not once. Not in twenty years.
That is the bar rConfig has just set. This post is the receipt.
It is also a direct, public challenge to every other vendor in the network configuration management space that has been quoting scale numbers without evidence. The test bed we used is open source, MIT licensed, on GitHub. Run your product against it. Publish your numbers. Or stop claiming scale you cannot prove.
How we got here
rConfig is engineered for scale. It always has been. Queue-driven concurrency, autoscaling workers, indexed property extraction, a diff engine built to chew through multi-megabyte configs without flinching, retry logic designed for networks that misbehave because real networks always do. The architecture has been in production at customers for years, and we have always been confident in what it could do.
Confidence is not the same as proof. When the opportunity to deploy rConfig at one of the largest ISPs in North America at fifty thousand devices crossed my desk eighteen months ago, I made the call that I was not signing that contract on confidence alone. The customer deserved evidence. So did we.
The problem was that no version of rConfig had ever been pointed at fifty thousand devices, because nowhere in the world can you actually assemble fifty thousand real Cisco boxes for a test. Not in our lab, not in any lab. Virtual environments like GNS3, EVE-NG, and Containerlab break long before you get to five-figure device counts on commodity hardware, because each virtualised IOS image still wants real CPU, real memory, real licensing in some cases. Mocked SSH servers prove nothing useful, because they do not behave like routers under realistic load.
Every meaningful test bed for an NCM at fifty thousand devices either does not exist, or has been kept private by whichever vendor built it. Probably the latter, in fairness. The reason vendors do not publish their scale evidence is rarely that they have nothing to hide.
We had a choice. Ship on confidence, like everyone else. Or build the test bed that would let us prove it, and put rConfig through the kind of trial by fire that no NCM product I am aware of has ever publicly survived.
We built the test bed. It is called rConfig-sim, and it is now in production use, on GitHub, and free for anyone in the world to run.
What rConfig-sim actually is
rConfig-sim is a Go program. MIT licensed. Single static binary. It stands up tens of thousands of simulated Cisco IOS devices on one Linux host. Each simulated device runs a real SSH listener with real authentication and serves a realistic configuration body that can be tuned from a few kilobytes up to several megabytes. From rConfig's perspective, or from the perspective of any tool that talks SSH to network devices, rConfig-sim is indistinguishable from a rack of physical kit. The handshake is real, the auth is real, the prompt is real, the transfer is real.
The design choices were deliberate and uncompromising. Configs are served via a zero-copy mmap path so that disk IO on the simulator side never becomes the bottleneck and accidentally makes the platform under test look faster than it actually is. There is a Prometheus endpoint with per-device metrics so you can see exactly what the simulator is doing during a run. There is a fault injection layer that lets you specify a percentage of devices that will misbehave, and exactly how. Auth failures, mid-session disconnects, slow responses, malformed output, in any combination you like.
One Go binary. One Linux host. Fifty thousand routers' worth of behaviour. Open source.
There is nothing else like it in the industry. I have looked. If anyone reading this knows of a comparable open source test bed for NCM platforms, please send it to me, because I would genuinely like to see it. I do not believe one exists.
The runs
What follows is the actual journey from one thousand devices to fifty thousand. Every line is a real run, on stated hardware, with measured results.
We started at one thousand devices on an 8GB four-core host. Four minutes total runtime, 1.8 second average per job, fifteen percent CPU, 6.6GB of RAM. Comfortable, expected, baseline.
We pushed worker concurrency to one hundred. Same one thousand devices completed in two minutes, three second average per job, with the autoscaler intelligently flexing between thirty and seventy active workers based on queue depth. The platform was already showing the kind of efficient resource shaping you want from a system that knows its own capacity.
Five thousand devices was where we found the first real engineering signal. Six minutes to complete, four second average, P95 of 5.5 seconds. CPU above one hundred percent, disk IO climbing fast, and we hit MySQL connection saturation because we were running with the default 151 max connections against a workload that triggers around eighteen thousand jobs. We added a hot-table index, the batch finished cleanly, and we noted MySQL connection sizing as the first tunable. This is the kind of finding that happens once, in the lab, on simulated devices, before any customer ever sees it.
We rebuilt on 16GB and eight cores. Five thousand devices completed in five minutes, average 2.7 seconds, P95 of 5.75 seconds. No failures, clean run.
Ten thousand devices in eight minutes, 3.26 second average. We pushed MySQL to three hundred worker connections, kept the runtime, and removed the connection ceiling as a constraint. We then tuned Horizon's autoscaler to react to queue bursts faster, which trimmed the same workload to seven minutes and tightened the P95 distribution. The shape of the autoscaler matters as much as its ceiling, and rConfig's autoscaler shape is now tuned for exactly this kind of bursting load.
Twenty thousand devices in ten minutes. Average 2.65 seconds, P95 of five seconds, around ninety-one concurrent jobs sustained. CPU pegged, memory at 15GB, peak MySQL connections at 206. Mixed config sizes across small, medium, large, and huge. Storage usage hit 15GB across the saved configurations.
Forty thousand devices in nineteen minutes. Average 2.66 seconds, P95 of 5.9 seconds, ninety concurrent jobs sustained. Same shape, same resource ceiling, same response distribution. The platform was not surprised by load. It was processing the load.
Fifty thousand devices in twenty-one minutes. Mix of 20,000 small, 20,000 medium, 7,500 large, and 2,500 huge configs. CPU at ninety-five percent. Memory at 15GB. Disk IO at 18MB read and 74MB write. MySQL connection ceiling held throughout. Application stayed responsive throughout. Zero failures.
Read those last three lines again. Twenty-one minutes. Fifty thousand devices. Single host. The kind of host you can rent for a few euro an hour.
That is roughly forty devices per second sustained, end to end, against real SSH endpoints with realistic configuration sizes, on hardware that any operator on the planet can afford to run.
Then we broke it on purpose
A clean run on healthy devices is half the story, and any vendor showing scale numbers without fault injection is showing you only the easy half. Real networks have cranky boxes, bad auth servers, partial outages, slow links, devices that hang for reasons no one ever properly diagnoses. The interesting question is not what your platform does on the happy path. It is what your platform does when one device in twenty is misbehaving.
We ran ten thousand devices with a four percent failure rate, mixed across auth failures, mid-session disconnects, slow responses, and malformed output. Eight minutes to complete. Retries absorbed the failures. No collateral damage to the platform.
We ran twenty thousand devices with a five percent failure rate. Nine minutes. Application stayed up, the diff engine kept producing clean output for responding devices, failed devices ended up in the retry queue exactly where they should be. CPU and memory profile identical to the clean runs.
This is the result that matters most, and the one I am proudest of. rConfig was engineered for chaos from day one. We have always known the retry logic was sound, because we wrote it that way and we have seen it work in production for years. We have now proven it under controlled, reproducible chaos at five-figure scale, with documented fault percentages and documented outcomes. There is no other NCM product in the world that has published this kind of evidence. There may be other NCM products that could survive this kind of test, but until they publish, we are the only ones who have.
Why this matters, depending on who you are
The same set of numbers means quite different things depending on which side of the table you are sitting on. I want to walk through several of them.
For network operators, the practical message is that rConfig is the only NCM platform on the market with publicly documented evidence of fifty thousand device performance on commodity hardware, with fault injection results to match. If your fleet is anywhere from a few hundred to fifty thousand devices, rConfig has been measured against your shape and beyond it. You are not buying on extrapolation. You are buying on receipts.
For CIOs and CTOs evaluating NCM in 2026, the bar for acceptable evidence has shifted, permanently, today. You can now ask any vendor in your shortlist a simple question. "Have you run your platform against rConfig-sim, and if so, can you share the numbers?" Their answer tells you everything you need to know. There is no longer any excuse for vendors to refuse to publish scale evidence, because the test bed is free, open, and proven. If a vendor cannot or will not produce a number, that is itself the answer.
For competing NCM vendors, the era where scale claims were a marketing exercise rather than an engineering one is over. The fog you have been hiding behind is lifting whether you help it along or not. I am not trying to be cute about this. I have built and run a serious test bed, put my own product through it in public, set a bar that I do not believe any of you can match today, and made the test bed available so you can try. If you can match it, do, and welcome to the conversation. If you cannot match it, the customer base is going to start noticing the silence.
For automation engineers running Ansible, NetMiko, Nornir, or in-house Python against your fleets, the same problem we had is now solved for you, for free. Point rConfig-sim at your scripts and find out what they actually do at fifty thousand devices. The answer might delight you. It might not. Either is more useful than the answer most teams are working with today, which is "we have no idea, but we hope".
For investors and analysts looking at the network management category, the next twelve months are going to bifurcate the field cleanly. Vendors who can answer the rConfig-sim question and vendors who change the subject. That is a piece of due diligence that did not exist in this category until last quarter. It exists now.
Why this matters now, specifically
There is a particular reason this benchmark lands in 2026 and not in 2016, and the reason is not subtle.
Networks are getting bigger, faster than the teams that run them. AI infrastructure rollouts. Hyperscaler expansion. Sovereign cloud builds. Edge sprawl. Satellite ground stations. IoT fleets that look like networks because they are networks. The number of customers with five-figure device counts is rising sharply. Six-figure device counts are no longer a thought experiment. The budget and headcount available to manage those networks is not rising at the same rate, anywhere on earth.
At the same time, AI ops and intent-based networking are pushing config management from a quarterly chore towards a real-time control plane. If your NCM platform takes hours to pull a fleet, the feedback loop above it cannot close fast enough for the automation layer to do anything meaningful. Twenty-one minutes for fifty thousand devices is not a vanity number. It is a precondition for the kind of automation the largest networks in the world are actively trying to build right now, and it is a precondition that no other NCM product on the market has publicly demonstrated.
This is the moment the category had to deliver on, and rConfig is the platform that has delivered on it. Saying that out loud is not bravado. It is the result of two years of deliberate engineering and several months of disciplined testing, with the data to back it up.
We open-sourced the test bed. Here is why.
rConfig-sim is MIT licensed and on GitHub. We did not have to do that. There was a clear internal argument for keeping it as a competitive moat. We chose openness instead, on purpose.
The reason is straightforward. The only way to fix this industry's evidence problem is to make verification cheap. If anyone, anywhere, can run our test bed against any NCM tool, including ours, and publish the numbers, then scale claims become testable in a way they have never been before. That is good for customers. It is good for honest vendors. It is uncomfortable only for the ones who have been bluffing for twenty years.
I expect rConfig-sim to become the de facto scale benchmarking tool for the entire network configuration management category over the next two years. Not because I am modest about it, but because there is nothing else of comparable capability and there is no good reason for anyone to build a competing one. The job is done. Use ours.
I would love to see other vendors run rConfig-sim and publish their results. I do not expect most of them to. The ones who do will earn a level of trust that twenty years of marketing copy has not bought any of them. The ones who do not will, eventually, have to explain why.
The new bar
Until somebody shows otherwise, fifty thousand devices on a single 16GB eight-core host in twenty-one minutes, with five percent fault injection absorbed cleanly, is the bar for what a network configuration management platform should be capable of in 2026.
rConfig set that bar. We have the data. The simulator is open source so anyone can verify it.
To the rest of the industry, the position is simple. Match it, beat it, or stop quoting scale numbers you cannot prove. Pick one.
To everyone running a network at any size, anywhere in the world, the position is even simpler. The fastest, most rigorously tested, most publicly proven NCM platform in the category is now available to you, and there is no longer any reason to settle for less.
We engineered rConfig to win at scale. We built rConfig-sim to prove it. The numbers are in. The bar is set.
Your move.
Stephen CTO, rConfig
rConfig-sim on GitHub: https://lnkd.in/da4NJ97c
About the Author

Stephen Stack
CTO, rConfig
Stephen is the creator of rConfig and a veteran network automation engineer with over 15 years of experience. He is dedicated to solving the complexities of network management through open-source innovation and enterprise-grade tooling.
Follow on LinkedInRead Next

Why rConfig-sim Models Ciena 6500 TL1: Simulating Carrier-Grade Optical Transport

Ciena 6500 TL1 GNE/RNE, Explained, and How to Simulate It at Scale
